
在持續了一年多的「百模大戰」後,近期,AI巨頭們終於開始近身肉搏、瘋狂降價,類似於很多傳統行業,AI行業也開啓了以價格換市場的老套路。
很多人可能不太清楚,本輪大模型降價的第一槍,是一家金融公司開打的。
5月初,著名量化私募幻方宣佈,旗下的AI公司深度求索DeepSeek發佈第二代MoE模型DeepSeek-V2,該模型API定價為每百萬Tokens輸入1元、輸出2元(32K上下文),價格為GPT-4 Turbo的近百分之一。
幻方作為量化領軍公司,很早便儲備了大量的GPU顯卡,本次率先降價,也體現了公司開拓AI業務的決心。
5月13日,全球AI的領軍企業OpenAI祭出「王炸」,發佈新旗艦模型「GPT-4o」,該模型更接近真人思維,可以實時對音頻、視覺和文本進行推理,更重要的是,價格僅為GPT-4 Turbo的一半。從OpenAI過往的動作看,降價也一直是其升級的主旋律。
5月15日,國内AI巨頭字節跳動也加入「降價潮」,公司旗下的豆包主力模型為0.8元/百萬Tokens,相當於0.8厘/千Tokens,即0.8厘就能處理1500多個漢字,號稱比行業價格便宜了99.3%,大超市場預期,也讓AI大模型的API調用成本邁入「以厘計價」的時代。
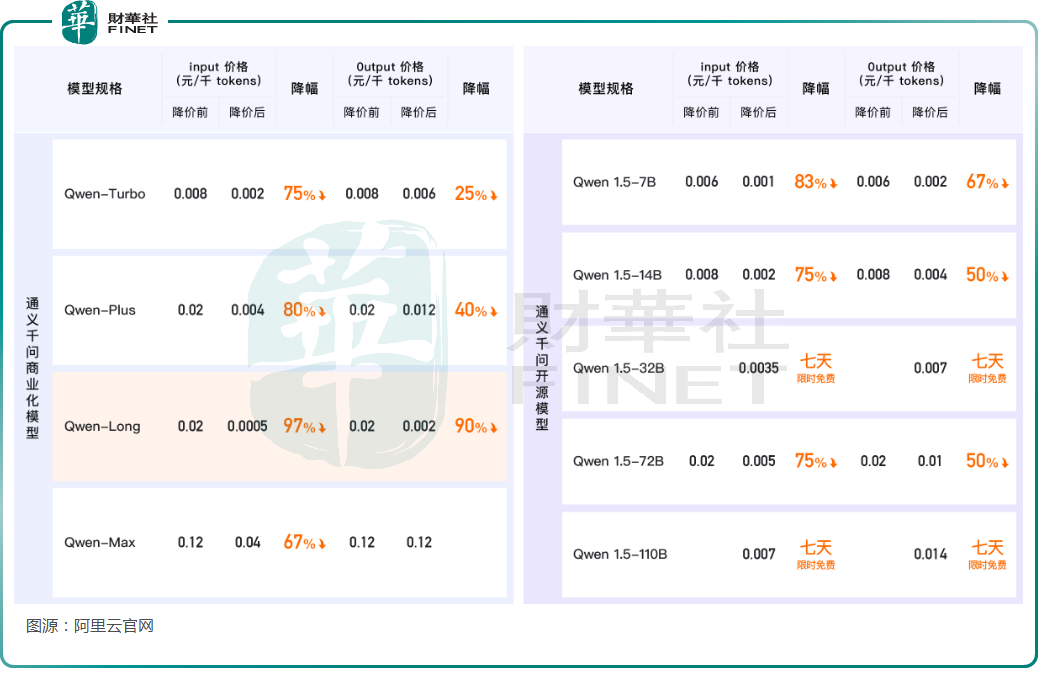
隨即,在5月21日,阿里雲宣佈通義千問大模型降價,其中GPT-4級主力模型Qwen-Long降價幅度達到97%,API輸入價格從0.02元/千tokens降至0.5厘/千tokens。這意味著用戶以1元錢可以買200萬tokens,相當於5本《新華字典》的文字量。
與此同時,一直押寶人工智能的百度,宣佈文心大模型的兩大主力模型ERNIE Speed和ERNIE Lite全面免費,立即生效。據悉,這兩款模型支持8k、128k上下文長度,是目前百度文心大模型系列中服務用戶最多的模型型號。
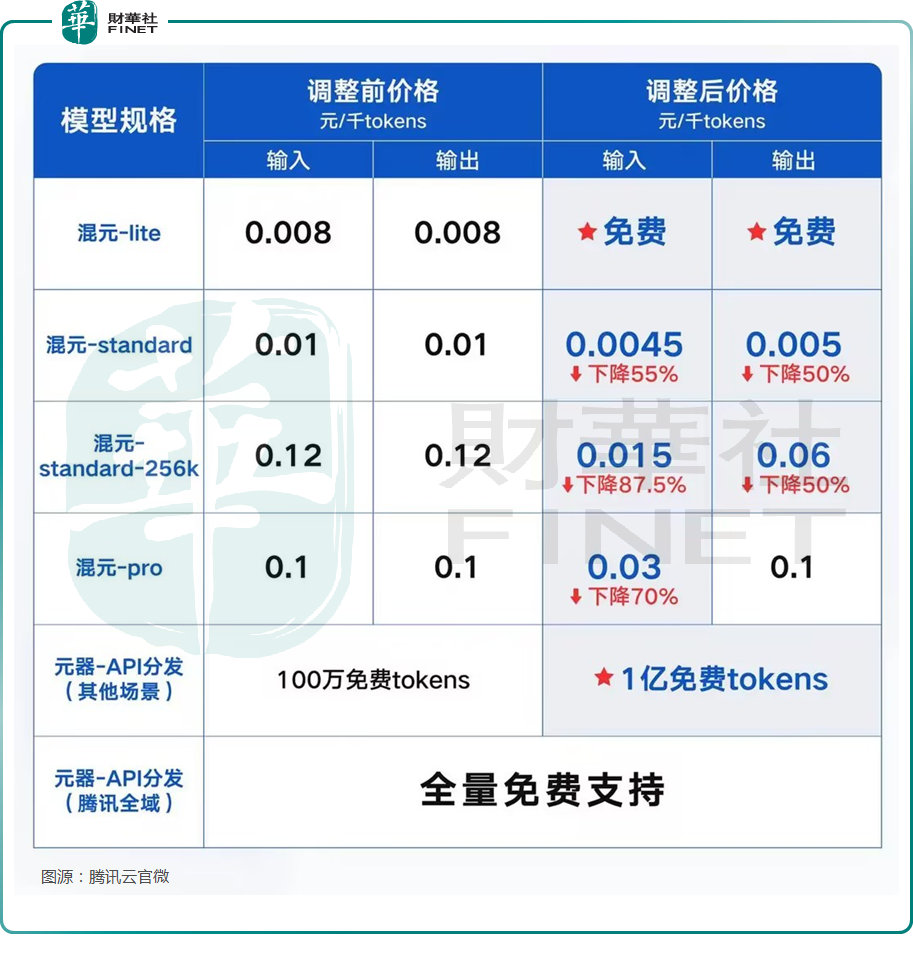
5月22日,騰訊雲公佈全新大模型升級方案,旗下主力模型之一混元-lite模型,API輸入輸出總長度計劃從目前的4k升級到256k,價格從0.008元/千tokens調整為全面免費。混元-standard API輸入價格下降55%,API輸出價格下降50%。新上線的混元-standard-256k,API輸入價格下降87.5%,API輸出價格下降50%。最高配置萬億參數模型混元-pro,API輸入價格降幅達70%。
某種程度上,大模型降價潮是資本湧入、市場競爭之下的必然產物。未來,能夠提供更高性價比服務的企業將脫穎而出,而無法適應變化的企業則可能出局或被整合並購。
過往來看,每一輪科技進步都伴隨著邊際成本的下降和生產效率的大幅提升。
比如芯片的誕生,將計算的邊際成本降到了趨近於零。隨後引發了計算機革命,出現IBM、惠普等科技巨頭。互聯網的誕生,將分發的邊際成本降到了幾乎為零,繼而引領了互聯網革命,出現了亞馬遜、谷歌和Meta等科技巨頭。
而AI技術也是一次生產力革命,目前受限於模型推理成本較高,AI應用普遍面臨較大的成本壓力。
本輪大模型的降價,本質上是將創造的邊際成本大幅度下降,後續開發者可以降低開發成本,更高效地開發AI應用,縮短開發周期,從而推動AI應用場景大規模的湧現。從這個意義上,大模型的降價,或是打開AI應用的關鍵「開關」。
知名企業家李開復認為,今年會是大模型應用的爆發元年。騰訊研究院亦認為,行業大模型有望加速在傳統行業落地應用,並在雲智一體的基礎設施支持下,朝多模態、人工智能體、端側及小型化等方向發展,更深入地嵌入各行業的工作流程中,從而促進生產力的提升。英偉達首席執行官黃仁勳此前就曾表示「下一場工業革命已經開始」。