
10年回報率超1500%,點擊瞭解「科技巨擘」策略,每天最低約2港幣,領取專屬優惠。
5月21日,阿裡雲宣佈通義千問大模型價格調整通知,主力模型降價高達97%,同日,百度智能雲宣佈文心大模型兩大主力模型全面免費。本月以來,已有多家公司宣佈旗下大模型產品降價,大模型價格戰已硝煙彌漫。
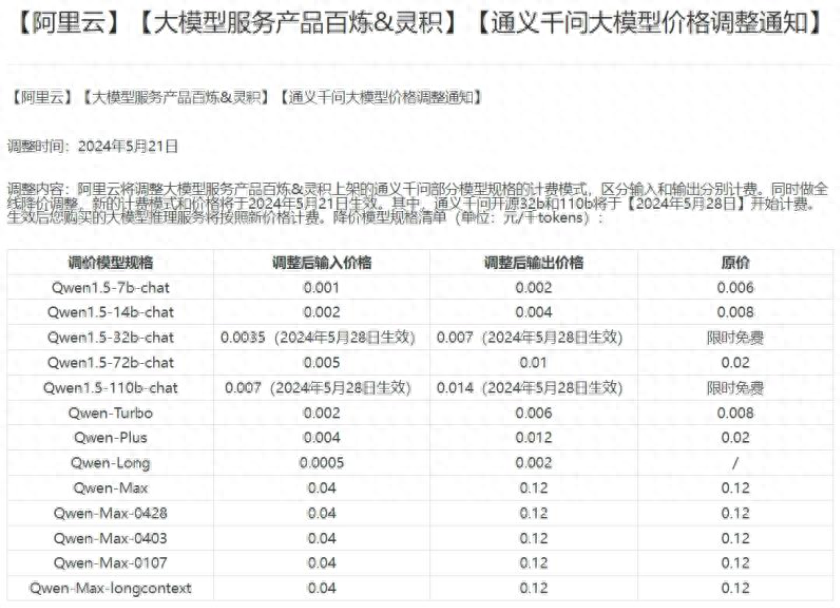
阿裡雲稱這意味著,1塊錢可以買200萬tokens,相當於5本《新華字典》的文字量。這款模型最高支援1千萬tokens長文本輸入,降價後約為GPT-4價格的1/400。
5月21日,百度智慧雲宣佈文心大模型兩大主力模型全面免費。分別為今年3月推出的兩款羽量級大模型ERNIE Speed、ERNIE Lite,支援8K和128k上下文長度。
近期,大模型行業內正在掀起一輪“價格戰”。5月15日,位元組跳動宣佈豆包通用模型Pro 128k版模型推理輸入價格為0.005元/千Tokens,豆包通用模型Pro 32k版模型推理輸入價格為0.0008元/千Tokens。
前段時間,幻方量化和智譜AI也宣佈調整旗下大模型價格。業內分析認為,此輪大模型降價潮,是各家廠商希望進一步搶佔市場,從而加速AI應用的商業化落地。
// 大模型價格戰硝煙彌漫 //
從5月召開的發佈會來看,各家在大模型價格上卷得越來越厲害了。
5月6日,幻方量化旗下DeepSeek(深度求索)發佈第二代MoE模型DeepSeek-V2,該模型API定價為每百萬Tokens輸入1元、輸出2元(32K上下文),價格為GPT-4 Turbo的近百分之一。
5月11日,智譜大模型官宣新的價格體系,新註冊用戶可以獲得額度從500萬 tokens 提升至2500萬 tokens,並且入門級產品GLM-3 Turbo模型調用價格從從0.005元 / 千tokens降低到0.001元 /千tokens,降幅高達80%。
5月13日,OpenAI發佈GPT-4o,不僅在功能上大幅超越GPT-4 Turbo,價格只有一半。
5月15日,位元組跳動豆包大模型在火山引擎原動力大會上正式發佈。據火山引擎(位元組跳動旗下雲服務平臺)總裁譚待介紹,經過一年的反覆運算和市場驗證,豆包大模型目前日均處理1200億Tokens文本,生成3000萬張圖片。“使用量大,才能打磨出好模型,也能大幅降低模型推理的單位成本。豆包主力模型在企業市場的定價只有0.0008元/千Tokens,0.8厘就能處理1500多個漢字,比行業便宜99.3%。”譚待表示,大模型從以分計價到以厘計價,將助力企業以更低成本加速業務創新。
可以看到,大模型降價既有GLM-3 Turbo這樣的入門模型,也有像性能接近GPT-4 Turbo的主力模型。而從OpenAI過去一年的動作看,降價也一直其升級的主線。
算上此次GPT-4o的發佈,2023年年初以來,OpenAI已經進行了4次降價。去年3月,OpenAI開放了gpt-3.5-turbo,每1000個token的成本為0.002美元,價格比此前的GPT-3.5模型下降了90%。
從去年3月OpenAI發佈GPT4到現在,其產品從GPT4升級到GPT-4o,輸入價格從0.03美元/1k tokens下降到0.005美元/1k tokens,降幅為83%;輸出價格從0.06美元/1k tokens下降到0.015美元/1k tokens,降幅為75%。
根據此前預期,大模型大致將按照每年50-75%幅度降本,也就是說,現在大模型的降本速度遠超預期。
10年回報率超600%,點擊瞭解「劍指道指」策略,每天最低約2港幣,領取專屬優惠。